STOCKAGE ET ORGANISATION DU WEB.
Le traitement et la gestion du langage naturel.
Au cours du temps, la production d’information à travers le langage a dépassé les dimensions de stockage humain, cela entraîne la conception de nouveaux moyens pour emmagasiner et organiser l’information, en effet, le monde cybernétique représente une façon de libérer de la place physique pour profiter de l’espace virtuel. Dans ce réseau d’informations, des mots et des concepts se mêlent par des représentations écrites en différentes langues, d’où la nécessité d’organiser cette multitude terminologique. Ce travail s’effectue à travers le catalogage, l’indexation, les bases de données terminologiques, les glossaires et les mémoires de traduction lors du traitement multilingue.
En ce qui concerne le fonctionnement de la langue, le linguiste explore tous les éléments linguistiques et métalinguistiques tant à l’oral qu’à l’écrit pour expliquer comment et par quels moyens l’individu communique et interagit avec ses compères. En effet, l’un des moyens le plus utilisé de nos jours, c’est l’ordinateur ; ainsi l’informaticien s’intéresse à comprendre la logique de l’information stockée en masse dans les machines. C’est le développement des ontologies – spécifications formelles explicites de termes d’un domaine et de relations entre elles – (GRUBER, 1993) que prétend structurer l’information créée en ligne par l’individu.
Il est opportun de mentionner que la linguistique et l’informatique font connaissance grâce à la linguistique du corpus, lorsque le spécialiste de la langue veut faire un approfondissement de l’analyse du discours. Il se sert des appareils pour enregistrer la langue orale. Son intérêt porte sur la parole naturelle pour classer le style du langage, la retranscription est nécessaire afin de visualiser les mots dans leur contexte. Cela ne demande pas une maîtrise exhaustive de l’informatique, contrairement au traitement technique exécuté par les spécialistes des ordinateurs, lors de l’extraction terminologique et, de l’étiquetage morphosyntaxique d’un texte.
Si nous revenons aux ontologies, il est nécessaire d’identifier les termes pour structurer l’information et pour que les machines reconnaissent automatiquement leurs emplacements. Par exemple, si un utilisateur d’internet cherche des informations médicales, il peut taper les mots clés et avoir, grâce aux ontologies, les liens plus pertinents contenant l’information recherchée.
Ces mots clés sont préalablement étiquetés, cette manipulation consiste à identifier les catégories grammaticales de chaque mot par segments à partir du contexte et des connaissances lexicales (HABERT 1997, p. 21).
Par conséquent, cette opération facilite la structuration et l’organisation informationnelle de la toile. Pour arriver à bien faire cette catégorisation morphosyntaxique, une forte maîtrise de la grammaire est requise; l’intervention du linguiste n’en reste pas moins souhaitable Or, cette tentative d’organisation devient de plus en plus complexe vu la quantité de données dispersées en internet. Il y a plus que le texte à ordonner, il y a maintenant des images, des sons, des vidéos, etc.
Les informaticiens essaient de mettre en place une sorte de standardisation d’organisation informationnelle à travers le web sémantique. Ce ne sont pas forcément les termes qui entrent en jeux mais les concepts qui agglutinent un ensemble de données. Voici la définition qui nous est fourni par la BnF : Le Web sémantique (plus techniquement appelé « le Web de données ») permet aux machines de comprendre la sémantique et la signification de l’information sur le Web, dans ce contexte la sémantique des données est décrite par des ontologies.[1]
Avec cette affirmation, nous confirmons l’interdépendance de l’informatique et la linguistique, d’autant plus qu’il y a la nécessité d’une grammaire formelle informatique pour la normalisation de l’information sur internet.
Enfin le dernier aspect à discuter de l’unification des disciplines concerne l’information multilingue. En effet, le linguiste est conscient de l’importance de l’apprentissage des langues étrangères pour communiquer et échanger l’information dans ce monde globalisé. Tant dis que l’informaticien se heurte au problème de la terminologie comparative et travaille avec des équivalences linguistiques pour structurer les données. Le procédé le plus courant pour réaliser cette correspondance, c’est la traduction (une pratique très demandée de nos jours via internet) Dorénavant, une nouvelle discipline dans ce domaine a surgi : l’ingénierie linguistique.
Pour comprendre l’organisation de la langue nous nous rapporterons à la classification des linguistes et des terminologues. Tout d’abord, commençons par la classification des registres proposée par la linguiste FERRARIS[2]. Elle précise que chaque individu a une manière particulière de s’exprimer et de nommer les objets. Pour nommer la « maison » considérée comme un terme standard, chaque interlocuteur l’appellera à sa manière : par exemple, nous avons donc un banlieusard, un interlocuteur courant, un écrivain et un architecte qui peuvent employer respectivement les termes suivants : le squat, la maison, la demeure, l’habitation. De ce point de vue, la langue se distingue par la production individuelle et son contexte. Cette réflexion est résumée dans le schéma ci-dessous où l’on discerne clairement les registres de la langue :
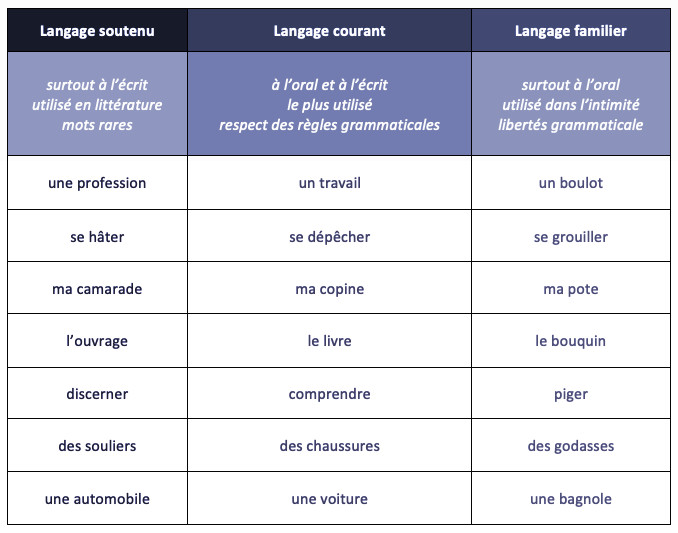
Nous pouvons affirmer que les interlocuteurs sont capables de reconnaître le style de parler de leur langue maternelle. Le point de repère étant le registre standard, considéré comme la langue courante. L’individu a tendance à parler d’une certaine manière selon l’environnement dans lequel il se développe. Le niveau de langue par ailleurs varie à partir de l’acquisition de connaissance. Nous pouvons constater qu’à partir de la l’intégration des formations professionnelles, le registre de langue est modifié (des nouveaux termes apparaissent) et l’individu commence à se spatialiser au fur et à mesure que qu’il maîtrise son domaine de spécialisation.
Apparaît alors, la nécessité de classer cette nouvelle production spécialisée par des concepts précis pour les distinguer de la grande quantité d’informations que possède l’individu.
À présent des terminologues et des lexicographes consacrent leur temps à élaborer des bases de données terminologiques.
Terminologue.
Le terminologue recense et définit les termes, trouve des équivalents, des synonymes et des variantes en langue maternelle et en langue étrangère. Le terminologue va créer un terme qui manque pour désigner un concept nouveau ou une nouvelle réalité.
Lexicologue.
Tandis que le lexicographe participe à la création d’un dictionnaire général en définissant les mots pour les répertorier.
Pour finir avec le travail du terminologue, il doit distinguer les différents registres entrant dans la conception de catalogues et la relation des termes entre eux. La correlation des mots et leur signification est importante du fait de la synonymie et de la variation[3].
[1] RACINE Bruno. Le Web sémantique. [en ligne] In : Bibliothèque Nationale de France. Disponible sur : https://www.bnf.fr/fr/professionnels/web_semantique_donnees/s.web_semantique_intro.html#SHDC__Attribute_BlocArticle0BnF (Page consultée le jeudi 28 juin 2012)
[2] Christelle FERRARIS, Registre, vocabulaire et classification [en ligne] In Revista Lengua y Voz, Numéro 1, 2011, pp. 20 – 35. Disponible sur : https://www.uaemex.mx/lenguayvoz/Revista/1/Articulos/Vocabulaire_familier.pdf (Page consultée le 19 Juin 2012)
Dans les coulisses de la royauté numérique.
Moritz METZ, journaliste pour ARTE TV France: Où se niche internet?
Disponible sur : Arte TV
Consulté en septembre 2013